

Data Federation (Zero-Copy): The new standard for data sharing
Introduction
Organisations are continuously looking for efficient ways to share data between platforms, particualry to surface data into data lakehouses and analytical platforms. Traditional data sharing typically involves copying and duplicating the data, which leads to inefficiencies and increased storage costs. A key approach to overcoming these challenges is data federation, also known as zero-copy. Many of the large software vendors (Salesforce, Snowflake, Databricks etc) are talking more and more about the importance of zero-copy and investing their efforts in open data sharing collaboration.
This blog post will delve into the intricacies of data federation, its benefits, how it contrasts with traditional data sharing.
What is Data Federation (Zero-Copy)?
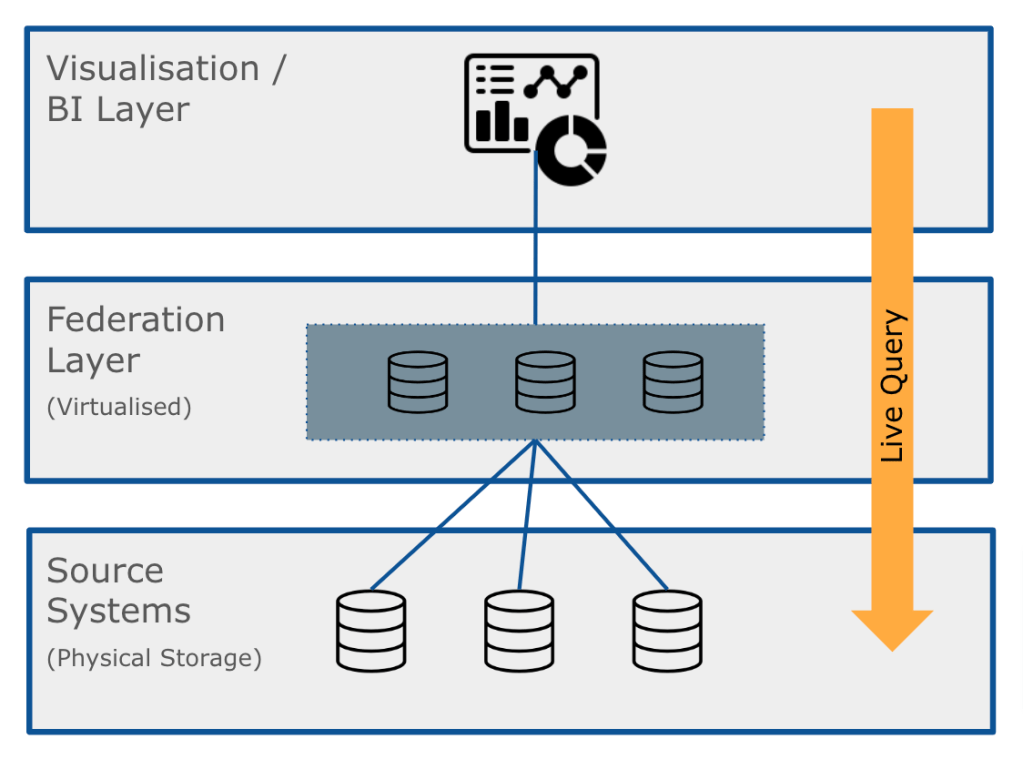
With data federation, data does not need to be moved or replicated to be accessed, analysed or processed (such as through a predictive model). Data remains (lives) in its original location. This approach significantly reduces data redundancy and storage requirements, making it a cost-effective data sharing solution.
By way of an example, order data and customer data maybe federated (queried live/in-place) within a BI platform directly from the systems the solutions they live in (lets say an Order Management and CRM system respectively).
Data can also be federated from other data lakehouses or warehouses.
Benefits of Data Federation
Data federation provides a number of benefits. The most obvious one is the drastic reduction in data duplication, which directly translates to cost savings in storage. It also reduces the need for ETL processes (though it does not remove it completely, since there may valid sceanrios to continue to physically copy data from one solution to another).
By allowing real-time access to data in its original location, data federation ensures data freshness and integrity, as there are no outdated copies. However, federation doesn’t always mean the data is real-time, just that a live read is done from where the data lives. If the data lives in a data warehouse, the data warehouse itself may only be refreshed once a day from another source.
Federation facilitates faster data access and insightful analytics, as it allows for queries across disparate data sources and types. It also enhances data governance and compliance, as there are fewer data copies to manage and secure (data remains only in its original location along with its original security design).
What are some considerations of of Data Federation?
Data federation involves integrating data from disparate sources, each with its own structure, format, and semantics. This then involves the creating a unified view and security model when brining multiple sources together and this must be done real-time since data is always consumed live.
Performance is another aspect. When federated queries need to pull data from multiple sources, it can result in increased latency, since things are reliant on how quickly the originating source system can serve the data back (the performance will be as long as the longest running query/source).
Summary
As data continues to grow in volume, variety, and velocity, organisations are increasingly recognising the need for efficient data sharing methods. By providing a unified view of data without the need for replication, it ensures data consistency, reduces storage costs, and facilitates faster, more accurate analytics. As we look towards the future, it’s clear that data federation is not just a trend, but the new standard for data sharing.

Leave a comment